Self-hosted AI agents
that learn how you work.
Messaging-native agents, encrypted secrets, sandboxed tools, learning memory, and an auditable operations surface - all on infrastructure you control. Run them from the chat apps you already use: Telegram, Discord, Slack, WhatsApp and more.

See it in action
One sentence.
A live pipeline.
A full DAG - parallel fan-out, multi-round debate, barrier sync, synthesis - built and running from a single natural-language prompt. No YAML. No scripting.
The ceiling of a single assistant
Personal assistants do not become platforms by accident.
Once an agent starts doing real work for real people, the missing pieces become obvious: memory, orchestration, isolation, and auditability.
One agent doing everything.
No specialization, no debate, one perspective on every question. Code, research, planning, and support all get squeezed through the same persona with no clear ownership or handoff.
Context that disappears.
Long conversations degrade. Context windows fill up, old decisions fall out, and the agent stops knowing why it chose a path. Without retrieval and recovery, deep work keeps resetting.
Prompt chains, not workflows.
No orchestration. No parallel execution. No schedules. You become the workflow engine: copy-pasting outputs between prompts, sequencing steps manually, and watching every run.
Plain-language control
Less setup friction. More operational control.
Describe the agent team or workflow you want, then refine it conversationally. Comis turns intent into agents, schedules, and DAG pipelines while keeping the underlying configuration available when you need precision.
Create a team in one message
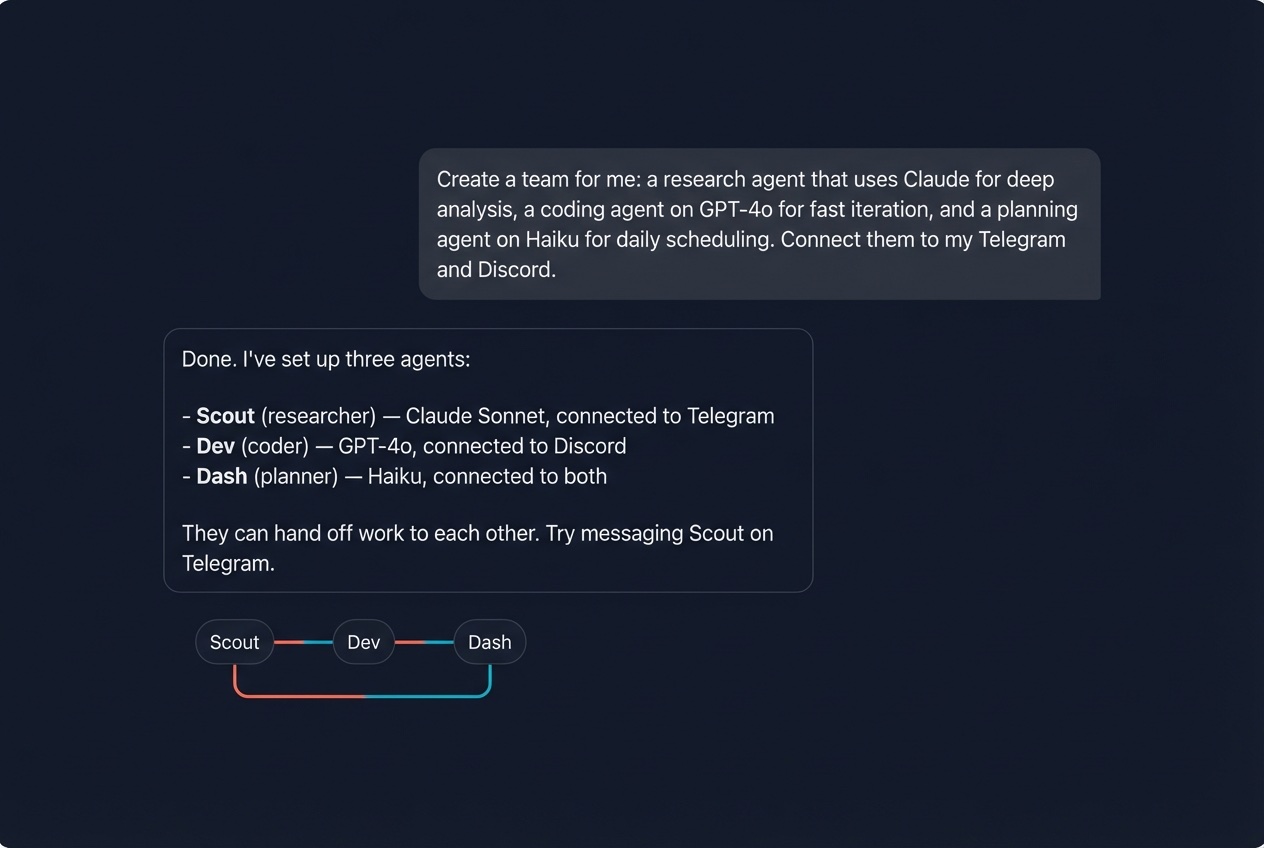
Three agents. Two channels. Different models. One sentence from you.
Build a pipeline by describing it
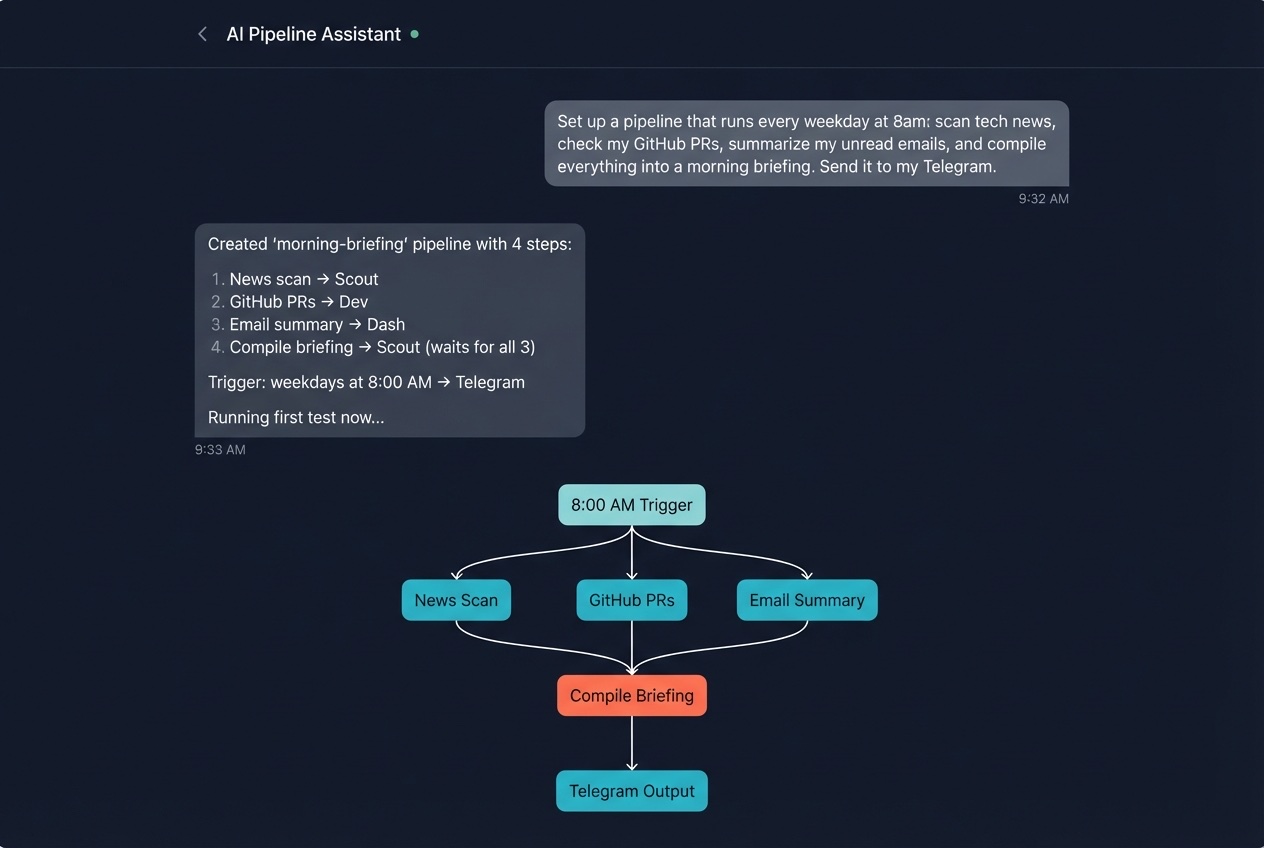
A full DAG pipeline - parallel fan-out, barrier sync, cron trigger - from a single sentence.
Evolve it conversationally:
"Add a step that checks my portfolio positions before the market opens. Have the analyst agent handle it."
"Added 'portfolio-check' step to morning-briefing. Scout will include it in the compiled briefing. Pipeline now has 5 steps."
No restart. Refine the workflow from the same conversation.
Other tools start with wiring. Comis starts with the outcome.
What you graduate to
A platform for many agents. Plain-language orchestration. Practical guardrails.
A platform, not a single bot
Run many agents for many people on one auditable install - each with its own model, memory, skills, and budget. Research, coding, support, and operations agents stay separated, hand work off to each other, and remain accountable to the same policy layer.
Orchestrate anything in plain language
Create agents, build DAG pipelines, and set schedules by describing the outcome you want. Use configuration when you need exact control; use conversation when you want to move quickly.
Built right from the ground up
When agents have real tools, infrastructure matters. Auth by default. Injection detection. Trust-partitioned memory. Encrypted secrets. Approval gates. Sandboxed exec where supported. A full audit trail. And they meet people where they already work - Discord, Telegram, Slack, WhatsApp, Signal, iMessage, IRC, LINE, and Email.







Quick Start
# One-liner installs Node.js and everything else (macOS & Linux)
$ curl -fsSL https://comis.ai/install.sh | bashWorks on macOS & Linux. The one-liner installs Node.js and everything else for you.
Verify with curl http://127.0.0.1:4766/health, then message your agent on any connected channel.
Read the docs →Security deep dive
Security that's engineered in, not bolted on.
Other AI agents ship fast and patch later. Comis was designed from day one around the question: what happens when an AI agent has real power and someone tries to abuse it?
Remote code execution: Attackers hijack agents through exposed endpoints and WebSocket connections.
→ Authenticated by default.
mTLS gateway, bearer token auth, no open ports without explicit configuration.
Unchecked tool access: An agent with shell and file access can read, write, and run anything on your machine.
→ Sandboxed exec by default where supported.
Tool execution is isolated with platform sandbox providers when available. Agents can be limited to their own workspace, and unsupported hosts are detected and logged rather than presented as fully isolated.
Prompt injection: Malicious instructions hidden in web pages or fetched content trick agents into executing attacker commands.
→ The LLM is treated as the attack surface.
Input is scanned, output is scanned, canary tokens catch leaks, and external content is wrapped and isolated so the model can never confuse fetched text for an instruction - layered runtime defenses, benchmarked.
Malicious skills: Community skills that hide exfiltration, injection, or breakout payloads.
→ Every skill is screened before it can run.
18 content-scanner rules covering exec injection, exfiltration, and XML breakout are applied at skill load time. (This is the canonical 18 - it belongs to the skill content scanner, not to log redaction.)
Malicious tool servers: A third-party MCP server could ship a known-bad package that runs the moment it starts.
→ MCP malware screening.
MCP packages are checked against the OSV malware database before they ever spawn for the first time.
Memory poisoning: Attackers modify an agent's persistent memory to change its behavior over time.
→ Trust-partitioned memory.
What an untrusted sender says can never overwrite what the system has verified. The trust weight is structurally frozen, so learning can never be poisoned into overriding a verified fact.
Credential exposure: API keys and secrets leaked through logs, tool outputs, or unencrypted storage.
→ Encrypted secrets.
AES-256-GCM at rest. Secrets are kept out of logs, tool output, and chat responses.
Credential exposure via agentic CLIs: An agent running shell commands can read any secret in its environment - `cat ~/.claude/.credentials.json`, `env`, `/proc/self/environ`. Handing a key to the agent process means it can steal and exfiltrate it.
→ Credential broker - keys never meet agents.
The real key never enters the sandbox. It stays in the daemon's encrypted store; the CLI runs with a placeholder. The broker injects the real credential at the TLS network boundary - `cat`/`env`/`/proc` inside the sandbox show nothing. Broker fails closed: no secret → 502, request never forwarded.
Destructive actions with no oversight: Agents that delete, send, or spend without anyone signing off.
→ Action classifier - fail closed.
Destructive actions pause for your sign-off via chat buttons. Unknown action types classify as destructive and fail closed, so a new capability can't slip through unguarded.
Data exfiltration: Agents tricked into sending private data to external servers.
→ SSRF protection.
Outbound requests to private networks, localhost, and cloud metadata endpoints are blocked.
No audit trail: When something goes wrong, there's no record of what happened.
→ Full audit system.
Every security-relevant action is logged, classified, and traceable with trace IDs.
Other agents ask you to trust them. Comis gives you reasons to.
Context intelligence
Context that stays useful.
Most AI agents degrade as conversations grow. Context windows fill up, earlier context gets dropped, and the agent forgets what mattered. Comis runs a multi-layer context engine before every LLM call - compressing intelligently, evicting dead content, and rehydrating critical context after compression.
The result: long-running agents stay coherent without blindly sending every old token back to the model.
Context Engine
Runs before LLM calls, keeps active state in view, and leaves room for DAG-backed recovery when older detail matters. Each layer is fault-isolated.
Thinking Block Cleaner
Strips extended thinking traces from older turns (default: 10 turns), keeping recent reasoning while reclaiming tokens from stale deliberation. Zero overhead for non-reasoning models.
Reasoning Tag Stripper
Strips inline reasoning tags from non-Anthropic providers persisted in session history. Always active regardless of the current model - sessions may contain mixed-provider responses.
History Window
Keeps the last N user turns per channel type. Group chats get tighter windows than DMs. Pair-safe: never splits tool-call/tool-result pairs. Compaction summaries always preserved.
Dead Content Evictor
Detects superseded file reads, re-run commands, stale errors, and old images. Replaces them with lightweight placeholders. O(n) forward-index scanning.
Observation Masker
Three-tier masking: protected tools (memory, file reads) are exempt, standard tools use a normal keep window, ephemeral tools (web searches) get a shorter window. Changes persist to disk for stable cache prefixes.
LLM Compaction
When context exceeds 85% of the model window, an LLM summarizes older messages into structured sections. Three-level fallback guarantees success. Cooldown prevents re-triggering.
Rehydration
After compaction, critical instructions, recently-accessed files, and active state are re-injected. Split injection keeps stable content in cache-friendly positions.
Objective Reinforcement
Subagent objectives are re-injected after compaction so delegated tasks stay on track even through context compression.
H = W - S - O - M - R
Token budget algebra
Every LLM call gets a precise budget: window minus system prompt, output reserve, safety margin, and a 25% context rot buffer.
3-tier disclosure
Progressive tool loading
Lean definitions always present, detailed guides on first use, irrelevant tools deferred. Progressive disclosure keeps tool definitions lean - the full tool surface for the context cost of a handful.
3-level fallback
Compaction resilience
Full structured summary with quality validation, filtered summarization, or a guaranteed count-only note if summarization fails.
DAG-backed recall
Lossless context engine
A depth-aware DAG keeps compressed history inspectable and recalls detail on demand via ctx_search / ctx_inspect. Compression stays reversible in-session instead of becoming a one-way summary.
Circuit breakers
Fault isolation
Each pipeline layer has its own circuit breaker. Three consecutive failures disable a layer for the session. Other layers keep running.
Memory that learns, not just remembers
SQLite + FTS5 full-text search and vector embeddings fuse across lanes for recall. An optional cross-encoder reranker re-reads candidates against the actual question for relevance; an optional entity lane brings back associatively related memories. Read-time temporal resolution answers with what's currently true without deleting history, repeated facts can consolidate into evidence-backed observations, and recall is trust-partitioned and trust-ranked so external content can never overwrite learned knowledge - all on-device.
Session continuity across restarts
JSONL session persistence with crash recovery. The context engine reconciles session state after restarts so agents can resume with the right state instead of repeating work. Microcompaction offloads large tool results to disk while keeping lightweight references inline.
Other agents forget what matters. Comis compresses, rehydrates, and learns.
Cost intelligence
Pay less. Do more.
Frontier models are powerful and expensive. Comis treats prompt caching as architecture, with 15+ shipped optimizations that cut measured session costs by 81%.
76-call Opus 4.6 session
$5.02 cached vs $26.42 uncached
Cache hit rate
Of input tokens served from cache
8-agent trading pipeline
788K tokens across a full DAG run
The pricing math nobody talks about
Anthropic charges a write premium to populate cache, then gives you a read discount on hits. The question is: which TTL actually saves money?
| TTL | Write Premium | Read Discount | Break-Even |
|---|---|---|---|
| 5 min | +$1.25/MTok | -$4.50/MTok | 28% read-back |
| 1 hour | +$5.00/MTok | -$4.50/MTok | 111% read-back |
1-hour cache writes are mathematically impossible to break even on Opus. Comis uses adaptive 5-minute TTL escalation, a practical strategy for keeping high-value context warm without overpaying.
Under the hood: 15+ dedicated optimizations including cache fence protection that prevents the context engine from breaking the cached prefix, sub-agent spawn staggering for pipeline cost sharing, and two-phase cache break detection that attributes every invalidation to its root cause. Gemini gets native CachedContent API integration with SHA-256 content hashing. Numbers below come from a real production session - see the cache forensics blog post for the methodology.
Read the full cache forensics storyWhat you can do
Real tools. Real workflows. Real results.
Context that stays useful
Comis trims dead content, compacts old turns, rehydrates active state, and can recover detail through DAG-backed context tools. Long sessions stay coherent without turning every request into a full transcript dump.
Automate real routines
Graph pipelines run multi-step work on demand or on a schedule. Scan the news, summarize email, check a calendar, compile a briefing, and deliver it to the right channel before the day starts.
Tools without blind trust
Built-in tools cover files, web search, browser automation, media processing, and sandboxed shell execution. Add the MCP ecosystem's 50+ servers - none bundled, you choose; Comis bundles none of them, so you choose exactly what to trust.
Voice, images, and files
Send a voice note, get a useful reply. Analyze images with vision models, transcribe audio with Whisper, Groq, or Deepgram, and generate speech with OpenAI, ElevenLabs, or Edge TTS.
Use the model that fits
35 catalog providers via pi-ai, local Ollama/LM Studio, and any OpenAI-compatible endpoint. Different agents can use different models, from local small models to frontier hosted models, while the same policies, credential handling, and audit trail stay in place.
Memory that learns, not just remembers
Comis combines SQLite, FTS5 search, vector recall, optional on-device reranking, trust-ranked memory, evidence-backed observations, and an opt-in feedback loop so useful memories get easier to retrieve over time.
Credential broker
Run API-key CLIs while keeping real secrets in the daemon's encrypted store. The tool authenticates through the broker; the agent never gets the key in its sandbox or output stream.
Lives where you already are.
Text, voice, images, files, reactions, and threads - adapted to each platform instead of forcing everyone into a new app.
Telegram Discord WhatsApp Signal iMessage LINE Email Who is this for?
A few ways people actually use Comis.
From a family group chat to a research fleet running in parallel - one install, separate agents, clear permissions, and a shared audit trail.
The family group chat
A household assistant in the chat everyone already uses. It keeps the shared calendar straight, nudges the right people, and answers from the running grocery note - on infrastructure you control.
The small-team ops bot
A small business triages WhatsApp and Slack overnight, drafts obvious replies for approval, and pings the team when a vendor sends an update - so the morning starts with decisions, not inbox archaeology.
The research fleet
One sentence turns into a fleet of agents that gather sources, debate the call, and hand back a single answer with reasoning shown. The orchestration is accessible to anyone who can type a request.
The developer & maker
A maker hands a coding CLI real work while the API key stays outside the agent process. The same setup compiles overnight pull requests, calendar events, and useful news into a morning briefing.
How it compares
What an agent platform should have.
Here's the bar Comis holds itself to, capability by capability. Want a head-to-head with named, excellent alternatives instead? Our honest comparison credits OpenClaw and Hermes where they win, and shows where Comis is the better fit.
| Capability | What you often get | Comis |
|---|---|---|
| Authentication | Often missing or optional | Required by default, mTLS support |
| Prompt injection | No detection | Input and output scanning, canary tokens, isolated external content - defense in depth - layered runtime defenses, benchmarked, not a single guardrail |
| Memory safety | Single trust level, poisonable | Trust-partitioned - your words vs. the internet's |
| Secrets | Often plaintext or process-level | AES-256-GCM encrypted at rest, never in logs or tool output |
| Credentialed exec - keys never in sandbox | Usually passes secrets into the process | Credential broker injects at the network boundary; the agent never receives the key |
| Tool access | Unchecked shell by default in many setups | Approval gates, per-agent policies, and sandboxed exec where supported |
| Skill safety | Install and hope | Allowlists, scope isolation, 18-rule content scan at load time |
| Network safety | No SSRF protection | Private network + metadata endpoints blocked |
| Audit trail | None | Every action logged and classified |
| Context management | Truncate and hope | DAG-backed recovery plus compaction: compression remains inspectable instead of becoming a black box |
| Tool overhead | All tool definitions on every turn | Progressive disclosure: lean definitions, just-in-time guides, context-aware deferral |
| Small model support | Same bloated context for all models | Model-aware scaffold: pruned schemas + focused tool sets + prompt-size budgets, plus reliability rails (goal anchor, JSON repair, self-correction) and a stricter security floor |
| Memory | Session-only, no recall | Memory that learns, not just remembers: trust-first recall, proof-accruing observations, optional reranking, and feedback |
| Budget | Unlimited spend | Three-tier budget guard: per-execution, per-hour, per-day |
| Agents | One does everything | A team of specialists |
| Channels | Varies | 9 platforms with platform-aware delivery |
| Models | Often locked to one provider | Any model, any provider |
| Source | Closed or partially open | Fully open source, Apache-2.0 |
Under the hood
Hexagonal architecture. Built to extend safely.
Core defines interfaces. Everything else - channels, tools, memory, LLM providers - plugs in from the outside. Adding a new channel or tool means implementing a port, not rewriting logic.
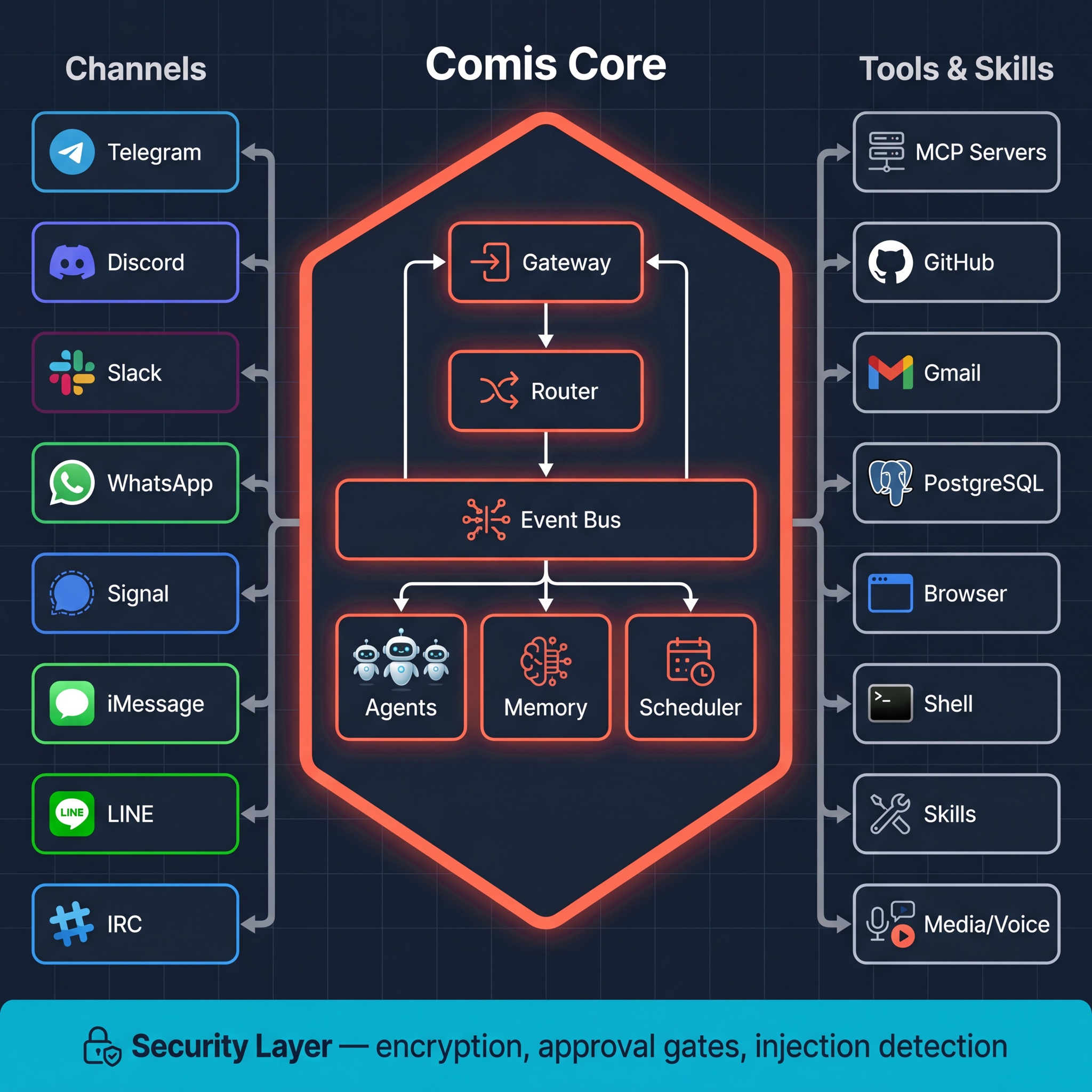
15 packages. TypeScript monorepo. Result-first error handling, typed boundaries, and architecture tests. Fully open source.
Fully open source. No catch.
Apache-2.0 licensed across all 15 packages. Every line is on GitHub. No open-core paywall. No cloud lock-in. No telemetry you did not ask for. Self-host it, fork it, audit it, extend it, and help shape the roadmap.
Security through transparency - not obscurity.
Star and fork on GitHubcomis (Latin, third declension) - courteous, kind, affable, gracious, gentle, polite. Also: elegant, cultured, having good taste.
We believe an agent you hand to your family, team, or company should earn that trust - asking before it acts, learning what matters, and keeping every action auditable. That is what isolated by design means: every person and every agent stays separate, capable, considerate, and accountable.
Self-hosted AI agents for teams, communities, and serious personal workflows.