A note on what changed
This post describes Comis's deterministic context pipeline: the original engine and still a fast, predictable option. Since publication, Comis also added DAG-backed recovery: older turns can compress into a zoomable summary the agent can drill back into with ctx_search, ctx_inspect, and ctx_expand. The pipeline mechanics below remain accurate for the deterministic path.
The token explosion problem
Let me paint the picture. You're running an AI agent on Telegram. A user asks it to analyze a codebase. The agent reads 5 files (8K tokens each), runs a few commands (2K each), thinks deeply about the architecture (4K thinking trace per turn), and has a 20-turn conversation building up context.
By turn 20, you're sending 180,000 tokens to the API. On Claude Opus, that's $0.90 per message just for input. And it keeps growing. Turn 30 might hit 250K tokens. Turn 40 approaches the context window limit.
The naive approach costs spiral:
Turn 10
~80K tokens
$0.40/msg
Turn 20
~180K tokens
$0.90/msg
Turn 30
~250K tokens
$1.25/msg
The insight that started the context engine: most of those tokens are waste. Old thinking traces the model no longer needs. File reads that were superseded by newer reads of the same file. Tool results from 15 turns ago that are completely irrelevant. The model is paying to re-read garbage.
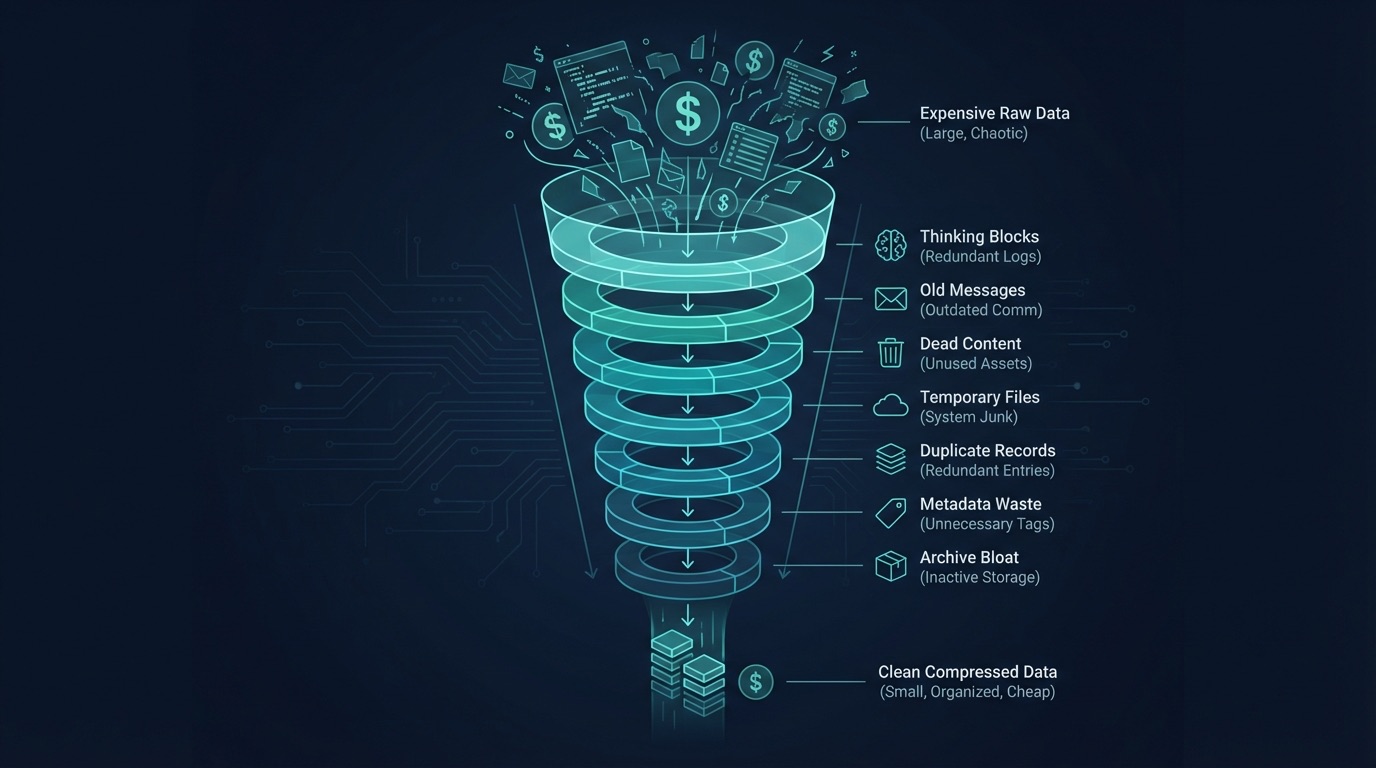
The pipeline: layer by layer
Every conversation in Comis passes through this pipeline before each LLM call. The layers run in order, each targeting a specific source of token waste. Every layer has a circuit breaker - 3 consecutive failures disables it. No optimization can crash the system.
Thinking Block Cleaner
Claude's extended thinking produces detailed reasoning traces - internal deliberation that guided the response. These are valuable for the current turn but become dead weight afterward. A 4K thinking trace from turn 5 is taking up space at turn 25 with zero benefit.
This layer strips non-redacted thinking blocks from assistant messages beyond a configurable keep window (default: 10 turns). Redacted thinking blocks (encrypted signatures the API needs for continuity) are always preserved.
Reasoning Tag Stripper
Different LLM providers embed reasoning in different ways. Anthropic uses structured thinking blocks (handled by layer 1). But DeepSeek and others use inline tags like <think>, <thinking>, <thought>, and <antThinking> embedded directly in the response text.
This layer strips those inline tags. It's always active regardless of the current model's capabilities, because sessions can contain messages from multiple providers - a user might switch models mid-conversation, and old DeepSeek reasoning tags would otherwise accumulate forever.
History Window
The simplest and most impactful layer. Caps conversation history to the last N user turns (default: 15). Everything older gets trimmed from the front.
But it's not a dumb truncation. The window is pair-safe - it never splits a tool-call/tool-result pair, which would confuse the model. And compaction summaries (from layer 6) are always preserved as anchors, so the model retains the gist of the trimmed conversation.
Dead Content Evictor
This is the one I'm most proud of from a pure engineering perspective. It uses forward-index O(n) analysis to detect provably superseded tool results.
If the agent read package.json at turn 5 and again at turn 20, the turn-5 result is provably dead - the newer read has the same or more recent content. The evictor replaces dead results with a 50-byte placeholder: [Superseded by newer read at turn 20].
It tracks 5 categories: file reads, exec results, web fetches, image analysis, and error tool results. Each has its own supersession rules. File reads supersede by path. Exec results supersede by command similarity. Dead error turns (tool-call that errored, never retried) are evicted entirely.
Observation Masker
This is the heavy artillery. When total context exceeds 120K characters, the masker activates and replaces tool result bodies outside a keep window (default: 25 most recent) with [masked] placeholders.
The key innovation is hysteresis. It activates at 120K but doesn't deactivate until context drops below 100K. This prevents oscillation - without it, the masker would activate, mask content (dropping below threshold), deactivate, then re-activate on the next turn when new content pushes it back over. The oscillation would invalidate the cache on every turn.
Protected tools (memory lookups, recent file reads) are exempt from masking. And there's a monotonic guarantee: once a tool result is masked in a session, it's always re-masked on subsequent turns. This prevents the cached representation from changing between turns.
LLM Compaction
The last resort. When context exceeds 85% of the model's window despite all previous layers, compaction fires. It sends the entire conversation to a cheaper model (Haiku by default) and asks it to produce a 9-section structured summary.
The 50+ message conversation becomes a single summary message. The model loses granular context but retains the gist. It's a brutal trade-off, but the alternative is hitting the context window limit and crashing.
Three-tier fallback: full summarization first. If that fails (model error, timeout), try filtered summarization (only recent messages). If that fails, inject a count-only note: "[53 messages compacted - context preserved in summary above]". The conversation continues either way.
Rehydration
After compaction destroys most of the context, rehydration strategically re-injects what was lost. Workspace instructions (AGENTS.md, max 3K chars), recently-accessed files (max 5 files, 8K each), and a resume instruction for seamless continuation.
The agent doesn't know compaction happened. It sees a summary of the old conversation, its workspace context, and a prompt to continue. From the user's perspective, the conversation just keeps going.
Objective Reinforcement
For sub-agents running delegated tasks, compaction is especially dangerous - the agent might forget why it was spawned. This layer re-injects the original task objective after compaction so sub-agents stay on track even through context compression.
It's the simplest layer (under 50 lines of code) but arguably the most important for multi-agent reliability.
The numbers don't lie
Here's what the pipeline produces in production. This is a real log entry from an 188-message session running an 8-agent stock analysis pipeline:
{
"tokensLoaded": 40112,
"tokensEvicted": 0,
"tokensMasked": 0,
"tokensCompacted": 0,
"thinkingBlocksRemoved": 0,
"budgetUtilization": 0.05,
"cacheFenceIndex": 54,
"sessionDepth": 188,
"durationMs": 1
} 188 messages. 40K tokens loaded. Budget utilization at 5%. Pipeline completed in 1 millisecond. The thinking block cleaner removed nothing (fence protected them). The observation masker is inactive (below threshold). The cache fence at index 54 is protecting the prefix from invalidation.
That same 188-message session without the context engine? Every message, every old tool result, every thinking trace sent to the API. Roughly 250K tokens. The context engine reduced it to 40K - an 84% reduction.
250K
Without context engine
→
8-layer pipeline (1ms)
40K
84% reduction
Design decisions that mattered
1. Never mutate in place
Every layer returns a new array. The input messages are never modified. This makes the pipeline predictable, testable, and debuggable. If a layer produces wrong output, you compare input and output - the input is pristine.
2. Circuit breakers on every layer
If the dead content evictor throws 3 consecutive errors, it disables itself. The pipeline continues with the remaining layers. No single optimization bug can take down the system. I learned this the hard way when a regex in the evictor caused a ReDoS on a pathological tool result - the circuit breaker caught it and the user never noticed.
3. The cache fence changes everything
The biggest architectural challenge was making the pipeline cache-aware. Layers 1, 2, 4, and 5 modify message content - which invalidates Anthropic's KV cache. The cache fence system tracks where the cached prefix ends and prevents layers from touching anything above it. This single feature improved our cache read/write ratio from 1.19x to 2.90x.
4. Observability is not optional
Every pipeline run emits a structured log with tokens loaded, evicted, masked, compacted, thinking blocks removed, budget utilization, cache fence index, and duration. Events fire on the typed event bus for the web dashboard. You can watch the pipeline work in real time. When something goes wrong - and in production it always eventually does - you know exactly which layer misbehaved.
Build it once, run it forever
The context engine runs before LLM calls across parent sessions, sub-agents, cron heartbeats, and graph pipeline nodes. It is designed to add negligible user-facing latency and works out of the box, while still exposing thresholds for operators who want to tune it.
If you're building AI agents that have long conversations or use tools heavily, context management isn't a nice-to-have. It's the difference between "$15 per session" and "$2 per session". Between hitting the context window at turn 30 and running indefinitely.
Want the full technical spec?
The context management page covers the cache fence, progressive tool disclosure, microcompaction, budget guards, and DAG-backed recovery. The context engine source lives in packages/agent/src/context-engine/.